Understanding React's state update
— React, Framework, Web


In this post
Ever wondered how React can manage single-page apps and is so fast? Understanding what's going on behind the scenes and how a website is displayed is key to being able to make wonderful modern web apps.
What is React?
Chances are most of you have already used React, or at least know what it is. As per Wikipedia, React is "an open-source JavaScript library for building user interfaces or UI components. It is maintained by Facebook and a community of individual developers and companies. React can be used as a base in the development of single-page or mobile applications". Its initial release was beginning of 2013, more than 7 years ago (yeah I know, already), and it is well-known for its declarative syntax: the JSX.
However, at the start, React started being adopted mainly because of its state management system. Call a state updating function inside a component and boom, everything updates at runtime, exactly like you want it, without reloading the whole app (hence the single-page possibility).
class HelloMessage extends React.Component {
render() {
return (
<div>
Hello {this.props.name}
</div>
);
}
}
ReactDOM.render(
<HelloMessage name="Taylor" />,
document.getElementById('hello-example')
);The stateless HelloMessage class renders a simple
<div>element, but I'd like you to note theReactDOM.rendermethod, we'll get back to it later.
The goal of this post is obviously not to explain how to code in React - I'll leave that to the official documentation that can be found here - but to make you understand how React knows which component to update, and when.
“You're a wizard saf'Harry”
In order to understand how React is able to differentiate between soon-to-be-updated components and should-stay-put components, we first need to understand how browsers display a page, and all the strange things that are happening behind (ok, maybe not all the things, but at least some things).
Hypertext Markup Language
Not a Turing complete language in itself, HTML is the standard markup language for every page displayed in a browser. Made out of nested elements defined by their tag, your website HTML structure can get really deep really fast without you even knowing what's inside, and that's not really a problem for modern browsers and computers most of the time. Add a bit of styling via CSS, some scripting feature thanks to JavaScript and you're good to go, you can finally send your file to your web browser thanks to HTTP, HTML e-mail, caching, local file or any other weird way.
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
<div>
<p>Hello chrome!</p>
</div>
</body>
</html><h5>parse me!</h5>
You guessed it, the next step is to read the html and find all linked resources to correctly display your web page. If the parser stumbles upon needed css, javascript, images or so, it will request all needed files from the web server and download them, probably caching some data and taking what's left of your RAM.
As a side note, html parsing uses tokenization, and it gets ugly really fast. If you want to have fun checking a cleaning tool, here's the official html tidy repo.
We can now get to building, which be split into 3 main parts:
- DOM building
- CSSOM building
- Render Tree building
"Wait a minute Anatole, DOM building as in ReactDOM.render() ?"
DOM building exactly as in ReactDOM.render(). The Document Object Model is a giant tree detailing where elements are displayed on the page, in relation to each others, where each node corresponds to an html tag.

Because we all have a Sherlock Holmes inside of us I'm sure you've already guessed what CSSOM stands for: Cascading Style Sheets Object Model. Instead of containing elements in each of its nodes, the elements' tags are the keys, and the css properties are the values in this model. Then javascript magically inserts itself into the newly constructed OMs and finally, everything is merged together to create one massive structure containing only what is necessary for display, called the render tree.
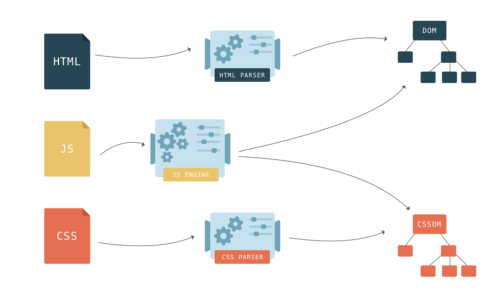
Display
“There's nothing wrong with having a tree as a friend” - Bob Ross
Bear with me for a few more lines we're nearly there, only two steps left; the former is the layout (or reflow) step. At this point we are in possession of everything needed to display what the user wants us to: we have elements, styling properties, maybe some scripts, media resources and text data. However, now that we have the what, we need the where, which ultimately depends on the viewport of the device. In order to make a box model which possesses all positions and sizes of our elements, there is no secret way: the browser needs to iterate over the render tree from the top down, in order to set elements properties depending on their parents (all relative measurements and scales will eventually become raw number values).
Last but not least, the painting step. Translating all the above information to colorful pixels is not as complex as you would think, but can be quite time consuming depending on your website's content.
You may have heard about the Flutter framework and how fast it is, the reasons are their optimized layout and painting steps tanks to Flutter's widgets management system. More info here.
The virtual DOM
I've told you multiple times that the DOM is heavy, and even though your browser and computer can manage it, DOM manipulation is really slow and every change triggers a screen painting action. This gets worse with the laziness of developers, and the lack of existing optimization in basic JavaScript frameworks. Let's say you are creating a todo list containing 1000+ elements (you might think about making it a bucket list at this point) and you edit the title of the 124th element, the non-optimized way would redraw all the 1000+ elements for one tiny change on your page.
React developers have found a simple and straightforward solution to address this issue, which is damn efficient: the virtual DOM. React creates and keeps a lightweight copy of the DOM containing all objects, the catch is the speed at which React can update its own DOM, on which object modification is super cheap. Once your code updates a component's state, React will compare its virtual DOM with a previous copy of the virtual DOM (made before the state update), if and only if objects have changed, React will update these objects on the real DOM.

This is why this.setState is asynchronous, React minimizes the number of DOM modifications. "There is no guarantee of synchronous operation of calls to setState and calls may be batched for performance gains." - React documentation.
The optimization goes even further with lists. You might have already stumbled upon this warning: Each child in an array or iterator should have a unique "key" prop; when React runs its diff algorithm on both of its virtual DOMs, lists need to be compared as well but diff detection on lists can be heavy. However, adding a key to each element reduces the number of needed operations, as described in the documentation.
In fact, VueJs uses virtual DOMs too
The fun fact about virtual DOMs is that the way they work is quite straightforward, and even though all the detailed optimizations can be quite complex, the core logic of React (JSX and virtual DOM) can be contained in a few hundreds lines of code.
Conclusion
Web development is a mess. React is dope, learn to use it correctly.